
Inhaltsverzeichnis
Google hat auf das Feedback der Nutzer gehört und die etwas in die Jahre gekommene Search Console erneuert. Die Kernfunktionen sind dabei noch immer dieselben. Das gratis Tool informiert weiterhin wie gewohnt über Nutzerzahlen, technische Probleme und die Indexierung der Seite – also all das, was wichtig ist, um auf Google gefunden zu werden. Doch macht sie dabei einen besseren Job als die Vorgängerversion? Um dir die Umstellung leicht zu machen, zeigen wir dir, welche Neuerungen es gibt und welche Funktionen aktuell noch fehlen.
Seit ca. einem halben Jahr zieht Google viele Funktionen der alten Search Console auf die neue Version um. Veränderungen mögen die wenigsten. Deshalb kursieren in den SEO-Foren auch verschiedene Meinungen über die Neuerungen. Dass bestimmte Funktionen noch fehlen, ist ein häufiger Kritikpunkt. Dabei macht die neue Version vieles besser. Während beispielsweise früher die Suchanfragedaten von maximal drei Monaten vorhanden waren, sind es nun 16 Monate. Viele Berichte, die in der alten Search Console auf verschiedene Menüpunkte aufgeteilt waren, wurden zusammengefasst. Dadurch informiert die neue Version schneller und übersichtlicher über verschiedene Punkte. Ein Beispiel hierfür ist der Abdeckungsbericht, der nun deutlich mehr Details anzeigt als früher.
Der Abdeckungsbericht
Der neue Abdeckungsbericht liefert ausführliche Informationen darüber, warum bestimmte URLs aus dem Google-Index ausgeschlossen wurden. Vor allem bei Duplikaten nimmt die neue Search Console es etwas genauer. So unterscheidet der Abdeckungsbericht speziell bei Duplikaten beispielsweise zwischen:
- Alternative Seite mit richtigem kanonischem Tag
- Duplikat – vom Nutzer nicht als kanonisch festgelegt
- Duplikat – eingereichte URL nicht als kanonisch festgelegt
- Duplikat – Google hat eine andere Seite als der Nutzer als kanonische Seite bestimmt
„Alternative Seite mit richtigem kanonischem Tag“ zeigt Duplikat-URLs an, die per Canonical Tag auf das Original verweisen. Hier ist das Canonical Tag also richtig implementiert und die Seite deshalb nicht im Index.
„Duplikat – vom Nutzer nicht als kanonisch festgelegt“ weist auf klassischen Duplicate Content hin, den du als Seitenbetreiber genauer untersuchen solltest. Die hier genannten Seiten wurden von Google als Duplikat erkannt und es gibt kein passendes Canonical Tag auf das Original.
Bei „Duplikat“ – eingereichte URL nicht als kanonisch festgelegt“ liegt dasselbe Problem vor, mit dem einzigen Unterschied, dass Google zur Indexierung der Seite aufgefordert wurde – z.B. durch eine Sitemap. In beiden Fällen wählt Google selbst eine geeignete Seite für den Index aus, die Google für das Original hält. Welche diese ist, lässt sich durch die Funktion URL-Prüfung herausfinden, die später noch im Detail betrachtet wird.
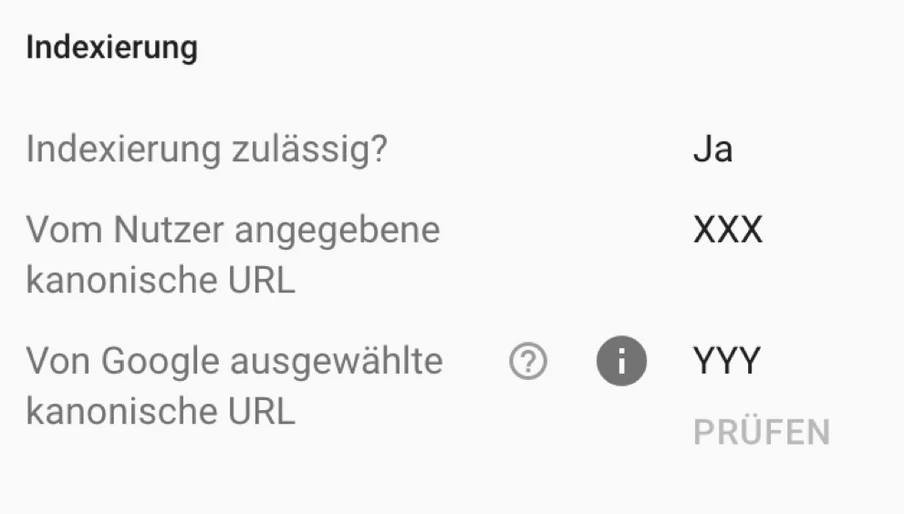
Die URLs unter dem Bericht „Duplikat – Google hat eine andere Seite als der Nutzer als kanonische Seite bestimmt“ sind vom Nutzer bestimmte „Originalseiten“, welche Google allerdings für das Duplikat hält. Hier interpretiert Google das vom Seitenbetreiber gesetzte Canonical Tag als falsch. Dies bedeutet also, dass der Seitenbetreiber und Google unterschiedliche Originalseiten auswählen. Dazu ist zu sagen, dass für Google das Canonical Tag lediglich ein Hinweis und keine Regel ist. Wenn Google das Canonical Tag für falsch hält, wählt Google eine geeignetere Originalseite aus. Dies kann z.B. der Fall sein, wenn eine vermeintliche Duplikatsseite besser intern verlinkt ist oder sich die Inhalte zu stark vom „Original“ unterscheiden.
Eine weitere hilfreiche Angabe, die du im neuen Abdeckungsbericht findest, ist „gecrawlt – zurzeit nicht indexiert“. Hierzu sagt Google lediglich: „Die Seite wurde von Google gecrawlt, aber nicht indexiert. Sie könnte jedoch in Zukunft indexiert werden. Sie brauchen diese URL nicht noch einmal zum Crawling einzureichen.“ Google hat also nach einem Crawl beschlossen, dass die Seite nicht in den Index genommen wird. Google nennt hier keinen Grund, warum die Seite nicht indexiert wird. Seitenbetreiber können dies allerdings als einen Hinweis sehen, dass die Seite keinen Mehrwert für den Nutzer darzustellen scheint – z. B. durch „Thin Content“. Als Seitenbetreiber solltest du deshalb diese Seiten prüfen und ggf. entfernen oder anpassen.
Neben den Duplikaten unterrichtet der Abdeckungsbericht weiterhin wie gewohnt auch über technische Fehler – beispielsweise 404-Headercodes. Neu ist hierbei, dass du Google sofort nach Behebung eines technischen Fehlers, zur Überprüfung der Fehlerbehebung auffordern kannst.
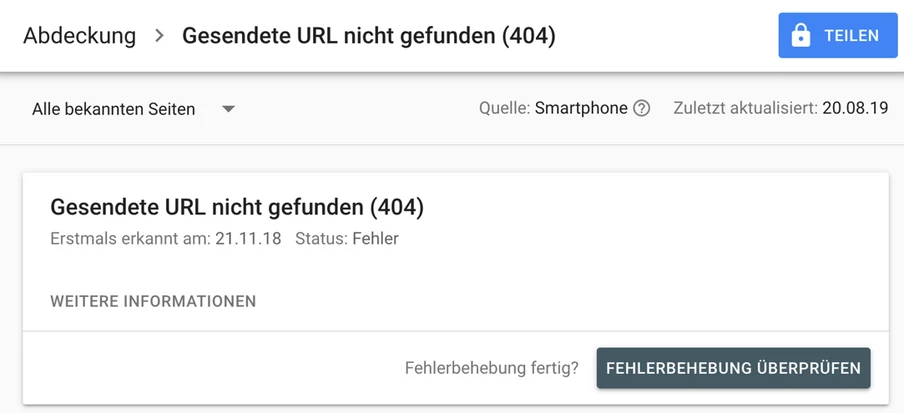
Identifizierte Fehler lassen sich in der neuen Search Console nun auch leichter teilen. Diese Funktion ist vor allem für größere Unternehmen hilfreich, bei denen mehrere Teams an einer Website arbeiten. Über weitere Herausforderungen und Tipps im SEO speziell für Großunternehmen kannst du im Whitepaper „Search Marketing für Konzerne und Großunternehmen“ nachlesen.
Die URL-Prüfung
Die URL-Prüfung erlaubt es dir, nähere Informationen zu einer bestimmten URL einzusehen. Dazu gehört etwa wann die Seite zuletzt gecrawlt wurde und welcher Google-Bot die Seite besucht hat (Bot für Smartphones oder für Desktop). Erhältst du beispielsweise im Abdeckungsbericht den Hinweis auf Duplicate Content, kannst du in der URL-Prüfung nähere Information darüber erhalten.
Mit dem Button „Live URL Testen” ist es möglich, die Seite durch Google rendern zu lassen, um ggf. Probleme zu prüfen. Hierbei zeigt dir Google neben dem HTML-Code noch die gerenderte Version der Seite an. Dabei wird jedoch JavaScript in der Regel nicht gerendert, sodass sich der Screenshot von der eigentlichen Seite unterscheiden kann.
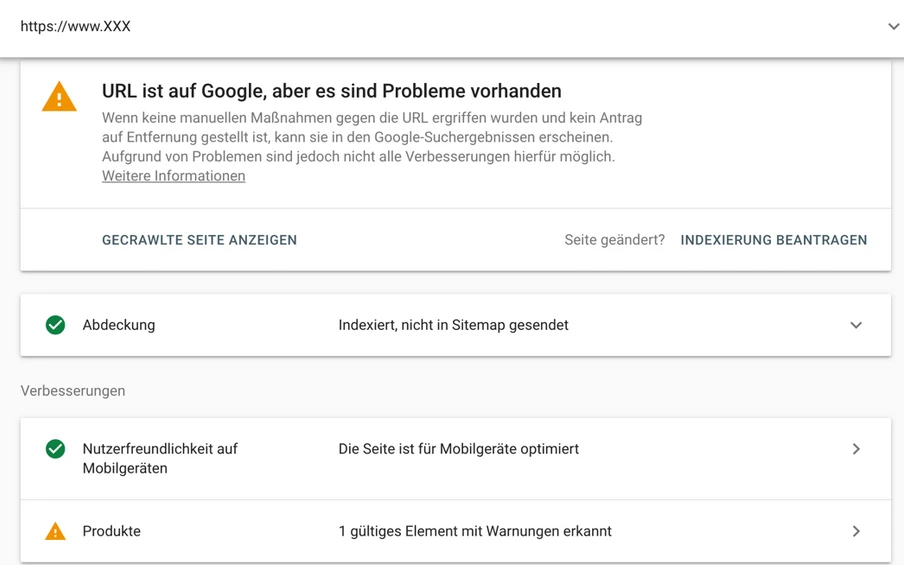
Die URL-Prüfung dient außerdem als Überblick für alle Probleme, die auf einer bestimmten URL existieren. Dazu gehören z.B. Probleme bei der strukturierten Datenauszeichnung. Im unteren Screenshot fehlen beispielsweise Daten zur Auszeichnung eines Produkts durch strukturierte Daten.
Der Leistungsbericht
Hier findest du wie gewohnt Daten über Klickzahlen, Impressionen, durchschnittliche Anzeigenränge und die Click-Through-Rate der organischen Suche. Allerdings wird mittlerweile nur noch der kanonische Traffic angezeigt. Das heißt, dass beispielsweise sowohl auf der mobilen als auch der Desktop-Variante Traffic erzeugt wird, die Search Console allerdings den gesamten Traffic einer Variante zurechnet. Diese hält Google für die „kanonische“ Variante. Häufig ist dies z.B. bei Websites mit einer „m.Domain“ der Fall.
Ebenfalls neu ist die „Darstellung in der Suche“ im Leistungsbericht – nicht zu verwechseln mit dem gleichnamigen Menüpunkt in der alten Search Console, welches nun unter „Verbesserungen“ zu finden ist. Während die alte Search Console nur Trafficzahlen zu der gewohnten organischen Suche anzeigt, werden in der Neuen auch die Daten für weitere Darstellungsformen der Suchergebnisse dargestellt. Schließlich kommen Nutzer nicht nur durch die normale Suche auf eine Website, sondern auch durch andere Google-Produkte wie Google for Jobs oder die Bildersuche.
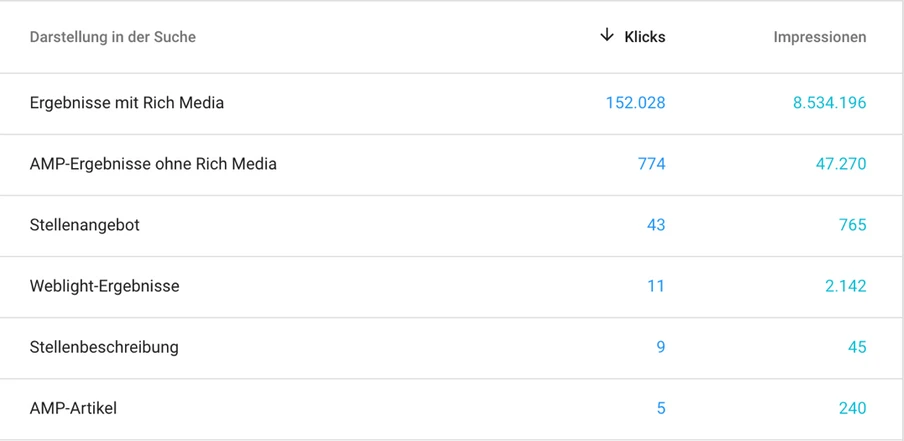
Im neuen „Darstellung in der Suche“-Bericht werden dir unter anderem Rich Media-Inhalte wie Rich Snippets angezeigt, also Ergebnisse von Seiten, die durch strukturierte Datenauszeichnungen erweitert wurden und sich deshalb von den Standard-Suchergebnissen unterscheiden. Auch Stellenangebote, die über Google for Jobs angezeigt werden, sind hier aufgelistet oder Trafficzahlen für Weblight-Ergebnisse. Eine Liste der angezeigten Ergebnistypen stellt Google in der Search Console-Hilfe bereit. Auf dieser fehlt aktuell jedoch noch die Rubrik „AMP on Image Result“, also die Trafficzahlen zur neuen „swipe to visit“-Funktion.
Google Discover-Suchergebnisse:
Für Seiten, die einen signifikanten Anteil des Traffics über „Google Discover“ erhalten, wird dir im Hauptmenü ein extra Menüpunkt angezeigt. Hier kannst du die Trafficzahlen der Discover-Funktion analysieren. Der Discover-Bericht ist dabei ähnlich wie der normale Leistungsbericht aufgebaut.
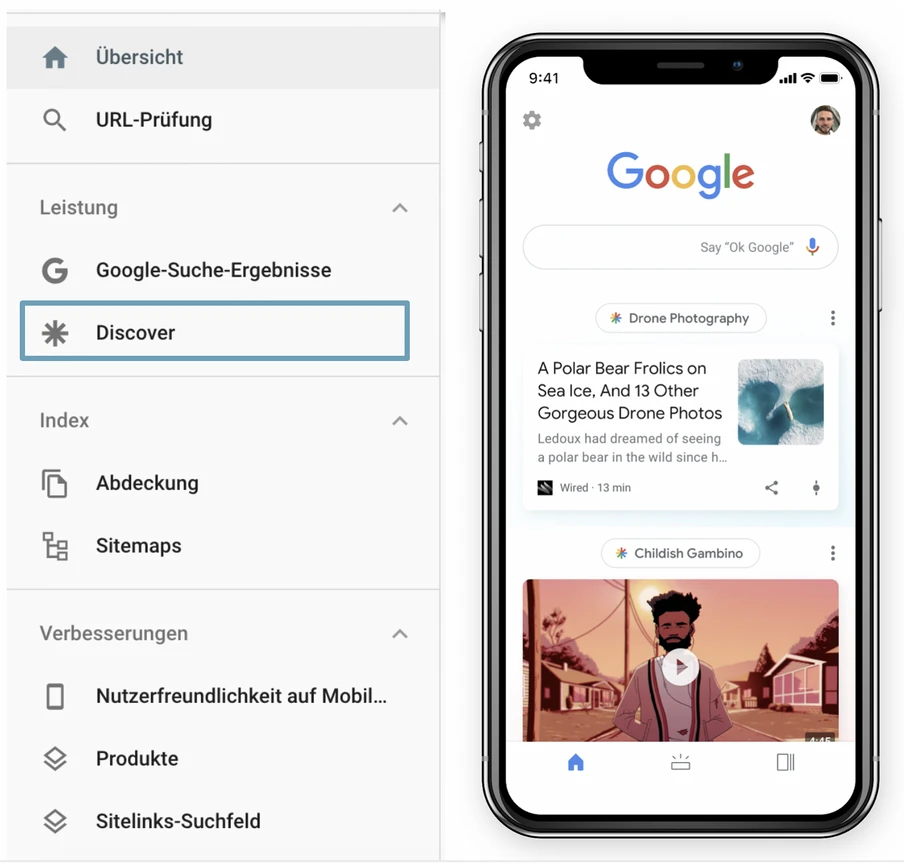
Es fehlen vor allem Funktionen, bei denen der Input des Seitenbetreibers gefragt ist.
Trotz vieler Verbesserungen und Neuerungen fehlen noch viele nützliche Funktionen aus der alten Search Console. Für viele ist dies ein Hauptkritikpunkt an der neuen Version. Folgende Funktionen sucht man Stand August 2019 noch vergebens:
Nachrichten: Hier informiert dich die Search Console nicht nur über Auffälligkeiten und technische Fehler, sondern auch über generelle Veränderungen wie z.B. die Umstellung auf das „Mobile First-Indexing“. Die Nachrichten sind noch über die alte Toolversion zugänglich.
Data Highlighter: Wem die strukturierte Datenauszeichnung im HTML zu kompliziert ist, der kann auf diese Funktion zurückgreifen. Durch den Data Highlighter kannst du bestimmte Bereiche deiner Website einfach mit der Maus markieren, und der Suchmaschine anschließend den jeweiligen Kontext für den Bereich mitteilen, also z.B. Preise auf deinem Onlineshop markieren.
Internationale Ausrichtung: Für die Suchmaschine ist manchmal nicht klar erkennbar, an welches Zielland sich eine Website richtet. Bei Top Level Domains wie .com oder .eu ist dies beispielsweise häufiger der Fall. Unter „Internationale Ausrichtung“ kannst du Google manuell mitteilen, welches Zielland die Seite hat. Außerdem erhältst du hier Informationen über verwendete und fehlerhafte hreflang-Tags, die zur Auszeichnung unterschiedlicher Sprachvariante genutzt werden.
URLs entfernen: Diese Möglichkeit, eine bestimmte URL vorrübergehend aus dem Google-Index auszuschließen, ist aktuell ebenfalls nur über die alte Search Console nutzbar.
Robots.txt-Tester: Diese Funktion zeigt die aktuelle Robots.txt-Konfiguration an. Sie hilft dir dabei zu prüfen, ob einzelne URLs ausgeschlossen werden. Die Robots.txt kann dabei live angepasst und mit verschiedenen URLs getestet werden, um neue Anweisungen zu testen.
URL-Parameter: Findet Google-Parameter URLs auf der Domain, werden diese hier angezeigt. Du kannst Google mitteilen, wie mit den Parametern umgegangen werden soll. Handelt es sich z.B. nur um Parameter, die den Seiteninhalt nicht verändern (z.B. Nutzertracking), kannst du Google darauf hinweisen.
HTML-Verbesserungen: In diesem Bericht wurden einem früher vor allem fehlende oder doppelte Meta-Titles und Descriptions angezeigt. Doppelte Title-Tags waren z.B. hilfreich, um Duplicate Content zu erkennen. Im neuen Abdeckungsbericht lassen sich Duplikate jedoch deutlich bequemer identifizieren. Der Bericht ist aktuell selbst in der alten Search Console nicht mehr erreichbar. Wer zu lange oder doppelte Seitentitel und Beschreibungen auf der Website identifizieren möchte, kann auf Tools wie Screaming Frog oder Ryte zurückgreifen.
Crawling-Statistiken: Hier berichtet Google über Crawlingaktivitäten der letzten 30 Tage. Durch die Dauer des Herunterladens einer Seite konnten auch grobe Rückschlüsse über die Seitenladezeit gezogen werden.
Was können wir aus der neuen Search Console über Google und SEO lernen?
Google wird immer besser darin, Websites zu verstehen. Dies spiegelt sich in den Änderungen der Search Console wieder. Hat einem Google früher noch doppelte Title-Tags angezeigt, werden in der neuen Version ganz konkret Duplikate aufgezeigt. Nicht nur das – Google zeigt einem auch URLs, bei dem es das Canonical Tag für falsch hält und verlässt sich hier nicht mehr rein auf die Angaben des Seitenbetreibers.
Dass Google immer mehr eigenständige Entscheidungen trifft, und weniger auf Anweisungen der Seitenbetreiber vertraut, ist in letzter Zeit vermehrt zu beobachten. So teilte Google erst kürzlich mit, dass das “rel-next“-
und „rel-prev“-Tag von der Suchmaschine ignoriert wird, da Google selbst paginierte Seiten erkennen und zuordnen kann.
Aktuell ist noch unklar, welche der noch fehlenden Funktionen übernommen werden. Vor allem Funktionen, bei denen Nutzer die Suchmaschine aktiv beeinflussen konnten, fehlen aktuell.
Kann das Fehlen dieser Funktionen bedeuten, dass für Google der Input von Seitenbetreibern weniger wichtig wird? Diese Frage wird wohl vor allem die Zeit beantworten. Google weist aktuell nur darauf hin, dass diese Funktionen fehlen, gibt aber keine Informationen zur Umsetzung in der neuen Search Console, obwohl diese die die Beta-Phase bereits verlassen hat. In einem neuen Video des Google Webmaster Youtube-Channels deutet John Müller außerdem an, dass bestimmte Funktionen nicht mehr relevant sind.
Für Seitenbetreiber und SEOs gilt also, dass sie sich nicht darauf verlassen sollten, dass Canonical Tags oder andere Anweisungen in der Search Console einfach so von Google akzeptiert werden. In der Search Console solltest du also immer die richtige Indexierung im Auge behalten.
Über den Autor:

Daniel Frent ist SEO Consultant bei der eology GmbH in Volkach und berät dort kleine Onlineshops bis hin zu großen börsennotierten Unternehmen. Bereits während seines E-Commerce-Studiums eignete er sich ein breites Wissen über SEO, SEA und Conversion-Optimierung an. Durch die Arbeit in der Agentur gehört für ihn die Nutzung verschiedenster Onlinemarketing-Tools zur täglichen Arbeit.
